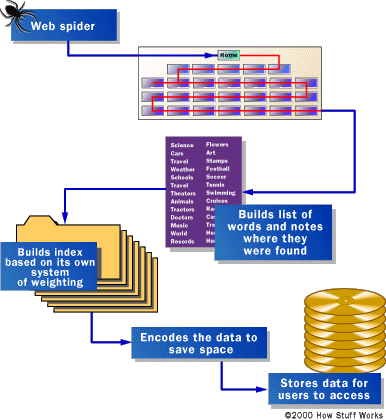
“Spiders” take a Web page’s content and create key search words that enable online users to find pages they’re looking for.
When a search engine’s spider looks at an HTML page, it takes note of two things:
- The words within the page
- Where the terms were found
Words occurring in the title, subtitles, Meta tags, and other positions of relative importance were noted for special consideration during a subsequent user search. The spiders were built to index every significant word on a page, leaving out the articles “a,” “an,” and “the.” Different spiders take different approaches.
These different approaches usually attempt to make the spider operate faster, allow users to search more efficiently, or both. For example, some spiders will keep track of the words in the title, sub-headings, and links, along with the 100 most frequently used words on the page and each word in the first 20 lines of text.
META TAGS
Meta tags allow the page owner to specify keywords and concepts under which the page will be indexed. This can be helpful, especially in cases in which the words on the page might have double or triple meanings — the Meta tags can guide the search engine in choosing which of the several possible meanings for these words is correct. There is, however, a danger in over-reliance on Meta tags because a careless or unscrupulous page owner might add Meta tags that fit very popular topics but have nothing to do with the actual contents of the page. To protect against this, spiders will correlate Meta tags with page content, rejecting the Meta tags that don’t match the words on the page.
All of this assumes that the owner of a page wants it to be included in the results of a search engine’s activities. The page’s owner often doesn’t want it showing up on a major search engine or doesn’t want the activity of a spider accessing the page. Consider, for example, a game that builds new, active pages each time sections of the page are displayed, or new links are followed. If a Web spider accesses one of these pages and begins following all of the links for new pages, the game could mistake the activity for a high-speed human player and spin out of control. To avoid situations like this, the robot exclusion protocol was developed. This protocol, implemented in the meta-tag section at the beginning of a Web page, tells a spider to leave the page alone — to neither index the words on the page nor try to follow its links.